| Q | |||||||
| Q |
If you get out a chess board, and put a queen in the lower left square, it's pretty clear that you can't put a second queen in the lowest row of the second column. That's the same row that the first queen is in. So there are really only seven choices available for the second queen. And the third queen only has six choices. It follows that there are 8 * 7 * 6 ... or 8! = 40,320 possible board positions to check for solutions. So combining the not-in-the-same-column rule with the not-in-the-same-row rule reduces the number of board positions to check by a factor of (8^8)/8! = 416.
There are algorithms that turn a counting integer into a unique permutation of a list. One could use this sort of thing. There are three reasons for not moving forward in this direction. First, the permutation algorithm is a bit complicated. It's nearly as long as the current program. Second, this permutation algorithm is fairly slow, though not anywhere near a factor of 416 slow. And its performance per call is proportional to the number of items to permute, in this case eight. Third, changing an exponential algorithm (8^8) into a factorial problem (8!) still gives you exponential time. If the board size is increased, the solution increases in time proportional to x^n of the board size. The permutation algorithm is handy. So perhaps it'll get a write up in some other series. This series has another direction. And if this code is converted to counting permutations, then it will be difficult or impossible to go where we're going.
| Q | |||||||
| Q | |||||||
| Q | |||||||
| Q | Q |
Let's return to the chess board. Put the first queen in the lower left square. In the second column, you can't put a queen in the lowest square. If you put the second queen in the second row, then the two queens are also attacking each other, this time diagonally. In fact, with the second queen in either of these positions, there are no queen positions of the remaining six queens that are solutions to the Eight Queens problem. You may as well move the second column queen up one more square. If you skip checking the positions with the other six queens, you've skipped 2*8^6 = 524,288 positions (of 16 million). And, you've skipped all these board positions with a two checks. It's easy to show that if the first two queens are as shown, the third column queen must be at least at the fifth row. To get the third column queen that high, four more checks are made, eliminating 4*8^5 = 131,072 boards. Big chunks of the problem space are vanishing, though they're vanishing in smaller chunks as the queens farther to the right are placed and checked. But this is the general way that the student in 1979 came up with his nearly zero time solution. It's also what Dijkstra did in his 1972 article about Structured Programming. However, this article isn't about Structured Programming (that would be a completely different rant) so much as it's about the technique Dijkstra used called Backtracking.
To make use of Backtracking you need to be able to generate a first board, a next board (and know if there aren't any more), you need to be able to check the partial solution, and you need to be able to print or otherwise identify the solutions you found.
Let's see how it works. The first board routine needs to simply place the first queen. In the check board routine, there's only one queen, so there are no attacks. The next board code knows that there is a possible solution, so it puts a new queen on the board in the next column. From here on, it's only check board and next board. The check board function needs to know how many queens are on the board so it can check rows and diagonals for attacks. In this case there are two queens, and they're in the same row, attacking. The next board function needs to know if the check board found an attack or not. Since there's an attack, it needs to move the rightmost queen up a row. When it finds a queen is at the top already, then it is removed, and the previous queen needs to be moved up. This is Backtracking.
For the Eight Queens problem, the initial solution space was so large, that it seemed hopeless. But it turns out that Backtracking is an approach that can be used to attack many of these combinatorial problems. The downside for Backtracking seems to be that it isn't very easy to decide how good the performance will become without first trying it. In this case, as queens to the right of the board are considered, smaller chunks of the problem space are eliminated. With increasing board size, does the problem stay exponential? Or is it something else? Knuth wrote about this issue in 1975. From my perspective, it doesn't matter. That's because Knuth is primarily thinking about the problem as a mathematician. Mathematicians want to think about a problem and come up with a solution. Programmers have another tool. They can write yet another program and see how it works. If the program takes too long, the programmer can tell the computer to count something of interest to help the analysis. Often this shows the programmer where to attack the problem next.
Don't agree with me? Here's an analogy. My favorite sorting algorithm is Shell's Sort. How long it should take is an open question. One advantage that it has over other algorithms is that an in-place sort doesn't require extra memory. It usually performs similar to n*log(n). In practice, it's usually quicker than Quicksort which has a best case of n*log(n) time, but requires more space. It doesn't bother me that its computation time is an open question.
In any case, let's look at a modification to the 8^8 version of the Perl program that does Backtracking. It's instrumented to find out how many rows needed to be checked (which is the number of next boards, and the number of diagonals checked. One should note that the board checks are faster than the previous version. That's because instead of checking all eight queens against all eight queens, it only has to compare the most recent queen to other queens. The previous queens have already been checked, and none are attacking. Since only 15,720 boards were checked, that's less than one in a thousand compared to the 8^8 solution. Fewer than one in three thousand diagonals need be checked. What does that mean for the order of computation? Not much. This code is written for an 8x8 board. It could be generalized to nxn, and then run, and then we'd find out... something. Since the checks are proportional to the size of the board, we'd expect time to rise faster than board size. However, the chunks that would be eliminated would be a larger proportion for larger boards. So, who knows? I'd be willing to bet that someone has written this up somewhere.
#!/usr/bin/perl
# Eight queens - incremental backtracking version.
# Chess board where eight queens are not attacking each other.
# Can't have two queens in the same column, so represent row numbers in columns.
# There are 8^8 (1e7) positions to check.
# The check for one queen per row gives you unique digits.
# If there's an attack between queens to the left, there's no
# need to keep checking to the right.
# This reduces the problem further.
# 92 winning boards. 15720 rows checked, 5508 diags checked.
# 0 seconds - likely less than 0.05 seconds.
# main
my $col = 0; # current column under consideration
my $x;
my @b; # board, 0 - 7 are columns, values are positions, 0-7
my $cnt = 0;
my $chkh = 0; # horizontal checks
my $chkd = 0; # diagonal checks
# set board to queens at bottom.
for ($x = 0; $x < 8; $x++) {
$b[$x] = 0;
}
while (1) { # The big loop, count to 8^8-1
# check for a win
if (&chkwin($col)) {
if ($col != 7) {
$col++; # Don't increment board, as new col is zero.
} else {
$cnt++;
# print "win ";
&prbrd();
$col = &incbrd($col); # increment the board
if ($col == -1) {
print "$cnt winning boards.\n";
exit(0);
}
}
} else {
$col = &incbrd($col); # Increment the board
if ($col == -1) {
print "$cnt winning boards. $chkh rows, $chkd diags.\n";
exit(0);
}
}
}
sub incbrd { # Returns $col. -1 when done.
my $col = shift;
$b[$col]++;
while ($b[$col] > 7) {
if ($col != 0) {
$b[$col] = 0;
$col--;
$b[$col]++;
} else {
return -1; # done
}
}
return $col;
}
sub prbrd { # Print the board
my $x;
for ($x = 0; $x < 8; $x++) {
print "$b[$x]";
}
print "\n";
# sleep(1);
}
# Assumes partial incremental board.
# Only have to check the rightmost column.
sub chkwin {
my $col = shift;
my ($x, $y, $a);
# Check for same row.
$chkh++; # How many horizontal checks.
for ($x = 0; $x < $col; $x++) {
if ($b[$x] == $b[$col]) {
return 0;
}
}
# Check for diagonal.
$chkd++; # How many diagonal checks.
$a = 1;
$y = $b[$col];
for ($x = $col - 1; $x >= 0; $x--) {
if (($y == $b[$x] - $a) ||
($y == $b[$x] + $a)) {
return 0;
}
$a++;
}
return 1; # 1 is good, 0 is not a win.
}
0;
Could this code be made faster? Sure. For one thing, any solution that is up/down mirrored is also a solution. So the left most queen only needs to go from 1 through 4. The mirror solution can be created by subtracting the row number for each column from nine. So one becomes eight. It's an easy change. It would produce all the answers in a little over half the time. Perhaps tricks like that allowed someone to compute the number of distinct solutions for a 26x26 board. Time spent counting alone would take forever. One expects that they used a compiled language. That would improve performance by a factor of about three hundred. This code could be converted to C without changing much of the look. And it could be converted to run on multiple processors fairly easily.
The interested reader might note that the general algorithm for Backtracking is presented as recursive, and the Eight Queens code that Wirth presented is also recursive. My Perl solutions are not. My policy on recursion is to introduce it if it helps with dynamic storage. In this case, restoring the previous state is a simple matter of changing the value of the column under consideration ($col). A further issue is parallelization. Multiple core processors are now common. We should be considering parallel computations. It looks pretty easy to start with my code and modify it for multiple processors. For example, it could be modified to consider the case where the first queen is set once, and not moved. All of the other boards with this first queen would be considered. Eight instances would be run, possibly at the same time. Perhaps something similar could be done with a recursive version, but it may not be so easy. It's something for future investigation.
This code was timed with a resolution of one second. Why work hard to reduce a fifty second program you need to run once to nearly zero? The answer is that these techniques are worth learning. There are other problems where even modern machines are hopelessly slow. We'll get to one of those soon.
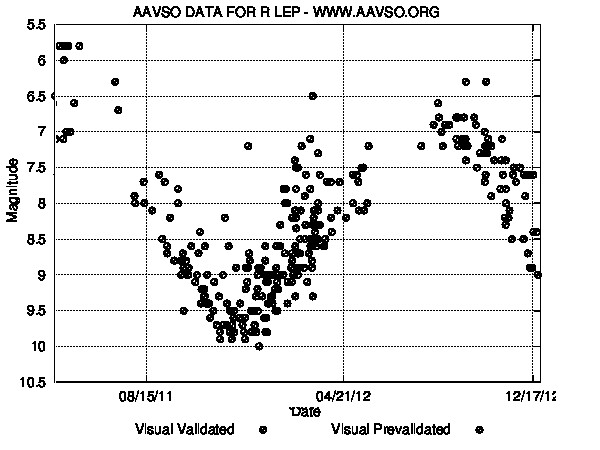 R Laporis is a variable star with a period of about 432 days (14 months). It most recently peaked near magnitude 6 in November 2012. So it should be faintest in June 2013 near magnitude 11. Here's the current
R Laporis is a variable star with a period of about 432 days (14 months). It most recently peaked near magnitude 6 in November 2012. So it should be faintest in June 2013 near magnitude 11. Here's the current 

